I’m going to break another blogging taboo. Namely, I admit the prolonged silence. Somehow, talking about the blogging platform hasn’t killed this blog so, who knows, maybe this won’t either. I’ve been busy changing from one awesome job to another, which I’ll talk about in a separate post. From now on, though, I’ll keep posting once a week, rotating a few persistent themes: technology (software engineering and machine learning), sports (cycling, running, training), travel and personal reflections. To keep up I’ll give myself roughly 1 hour per week to get the post published. We’ll see how that goes…
For the past 8 months I have been hard at work studying fundamental mathematics that most people learn in college: college algebra, calculus, linear algebra, probability theory and statistics. I figured it wouldn’t hurt to understand the basics that underlie modern engineering, software and machine learning. Just like learning to write doesn’t make one an author, learning these slightly advanced mathematics doesn’t make one a mathematician or an engineer. But it’s distracting not to know the basics and very difficult to learn on the job. Imagine learning to write while writing a scientific paper. Borderline impossible.
At some point I couldn’t escape the fatigue from all the MOOCS and books. I’ve completed 3 out 5 courses in the excellent Statistics with R Specialization specialization from Duke University. I got stuck on the Bayesian Statistics as my motivation was sinking and the difficulty of the course was skyrocketing. I decided it’s time to shift gears and mix the theory with practice before I lose my mind.
I couldn’t be happier to come across Elite Data Science Machine Learning Masterclass. It sounds cheesy and I debated for a while whether it’s the right next step for me. In the end, I found it totally worth the time and money. The course is highly applied and coherent. There’s no jargon and the most useful concepts are explained in plain English. Make no mistake, this doesn’t cover everything but the author is very upfront and clear about it. For me, though, it was just the right mixture of theory and practice. After all the dry exercises in calculus and linear transformations it felt great to tackle real datasets and try solving problems.
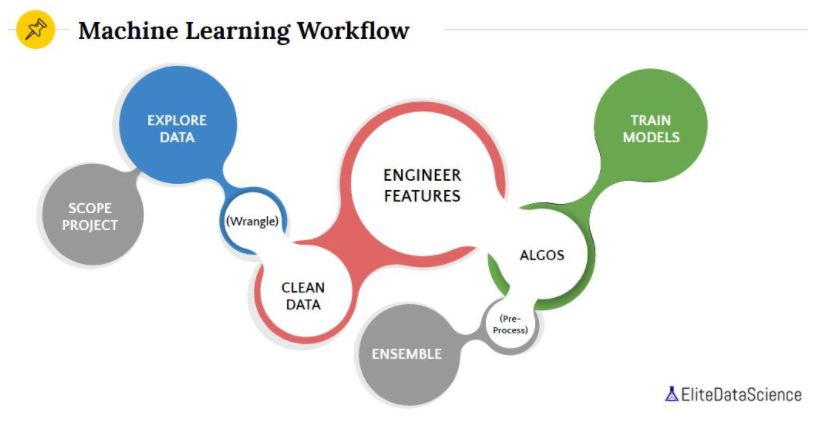
The best part of EDS is its emphasis on the research workflow and the fundamentals, from exploratory analysis all the way to the final delivery. The concepts are not anything new but the practice throughout all study projects reinforces the crucial steps. The good habits will persist even when the course is over.
The course consists of 4 projects. The first project is introduction and is super easy for someone with a software engineering background. The remaining 3 projects focus on regression, classification and clustering. I appreciate the hands-on nature and the lack of videos. I prefer project work to passively watching videos and then scrambling to figure out how they have anything to do with assignments or exercises. Videos do have their place but I was really tired of video lectures. The whole course took me about 4 weeks. I’ve spent about 3-4 hours on the weekend and I tried my best to practice 30 minutes a day during the week. Reinforcement and regular review help sink the concepts in.
Of course, the EDS course doesn’t cover everything but it’s a great step in the journey. EDS is a good reminder that real education happens when you face a real task and not just an isolated exercise. Despite doing project work as part of EDS I still stumbled when I took on a project outside of the course. Without exposure and practice courses are shallow and superficial. It is only when you face an ambiguous task it becomes clear how little you understood and remembered.
And that’s okay. As a first project I went to the UCI website that hosts public datasets for machine learning practice. I chose the wine quality dataset as my first project. Here’s just short list of how I failed:
- Mistakenly treated the problem as regression while it’s a classification problem.
- Stumbled on the issue of sparse classes (good and bad wine scores are under represented).
- Used the wrong metrics on multi-class classification.
- Came up with a model with a pretty low score despite grouping.
Still, it was a useful learning experience and I learned a couple of new things along the way. I also pivoted on the task and predicted wine color (red or white) based on physical measurements with very high accuracy. Sure, it sounds basic but there’s lot of satisfaction to be had from getting something done.
I’ve created a new repository for the present and future projects on Github: https://github.com/pisarenko-net/machine-learning
Machine learning is a vast field. There are tons of courses, books, articles and resources. It’s almost impossible not to get lost. Everyone you ask will come up with 10 things you need to know to get started (just check the recurring threads on Hacker News). Several lifetimes are probably insufficient to go through all that material. Personally, I decided to preserve my own sanity and take it easy. Specifically, for the foreseeable future I forbid myself from taking MOOCS, changing toolkits, reading books, following blogs and research papers. Instead, I’ll make use of the tools I already know to practice as much as I can. It’s alright to learn along the way with tutorials, articles and documentation but otherwise avoid timesinks.